
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
Tags
- java map 저장
- 코딩부트캠프후기
- 격파르타합격후기
- java최솟값구하기
- 작은수제거하기
- java map 출력
- java set 출력
- 프로그래머스제일작은수
- java set 저장
- 컴파일
- 항해15기
- 인터프린터언어
- java 자료구조 활용
- 격파르타비전공자
- java참조자료형
- java알고리즘문제풀이
- sqld자격증합격
- java map
- 항해99후기
- javaJVM
- java list 저장
- 격파르타후기
- 프로그래머스
- 격파르타장점
- 노베이스부트캠프
- java list 출력
- java기본자료형
- java알고리즘
- javaJRE
- 비전공자sqld
Archives
- Today
- Total
코딩과 결혼합니다
231014 - 자바의 정석 chapter 11 (컬렉션 프레임워크) 본문
728x90
⭐컬렉션 프레임워크
- 컬렉션 - 여러 객체(데이터)를 모아 놓은 것
- 프레임워크 - 표준화, 정형화된 체계적인 프로그래밍 방식
- 생산성이 높아짐, 유지보수가 용이함
- 컬렉션 프레임워크
- 컬렉션(다수의 객체)을 다루기 위한 표준화된 프로그래밍 방식
- 컬렉션을 쉽고 편리하게 다룰 수 있는 다양한 클래스 제공 (저장, 삭제, 검색, 정렬)
- java.util 패키지에 포함, JDK1.2부터 제공
- 컬렉션 클래스
- 다수의 데이터를 저장할 수 있는 클래스(ex : Vector, ArrayList, HashSet)
⭐컬렉션 프레임워크의 핵심 인터페이스
- List
- 순서가 있는 데이터의 집합, 데이터의 중복 허용
(ex : 대기자 명단) - ArrayList, LinkedList, Stack, Vector
- 순서가 있는 데이터의 집합, 데이터의 중복 허용
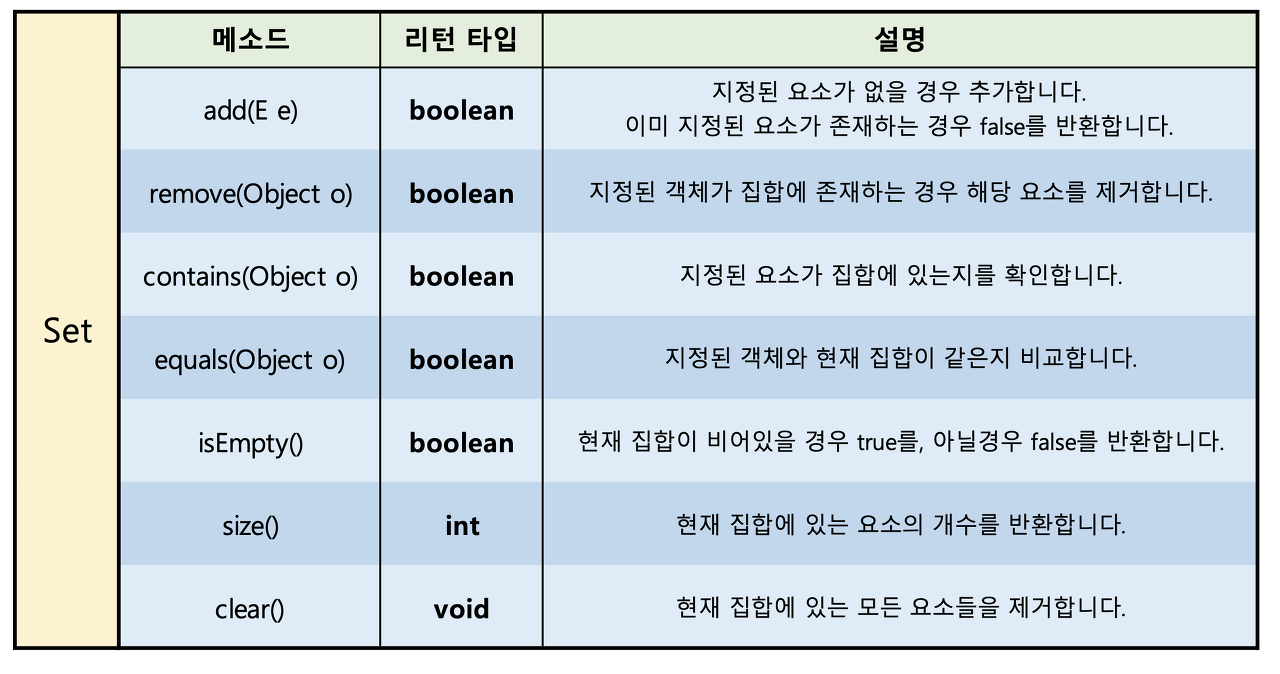
- Set
- 순서를 유지하지 않는 데이터의 집합, 데이터의 중복을 허용하지 않음
(ex : 소수의 집합) - HashSet, TreeSet
- 순서를 유지하지 않는 데이터의 집합, 데이터의 중복을 허용하지 않음
- Map
- 키와 값의 쌍으로 이루어진 데이터의 집합, 순서 유지x, 키는 중복을 허용하지 않고 값은 중복을 허용
(ex : 우편번호, 지역번호, ID/PW) - HashMap, TreeMap, Hashtable, Properties
- 키와 값의 쌍으로 이루어진 데이터의 집합, 순서 유지x, 키는 중복을 허용하지 않고 값은 중복을 허용
⭐컬렉션 인터페이스의 메서드
- List 인터페이스 - 중복⭕ / 순서 ⭕
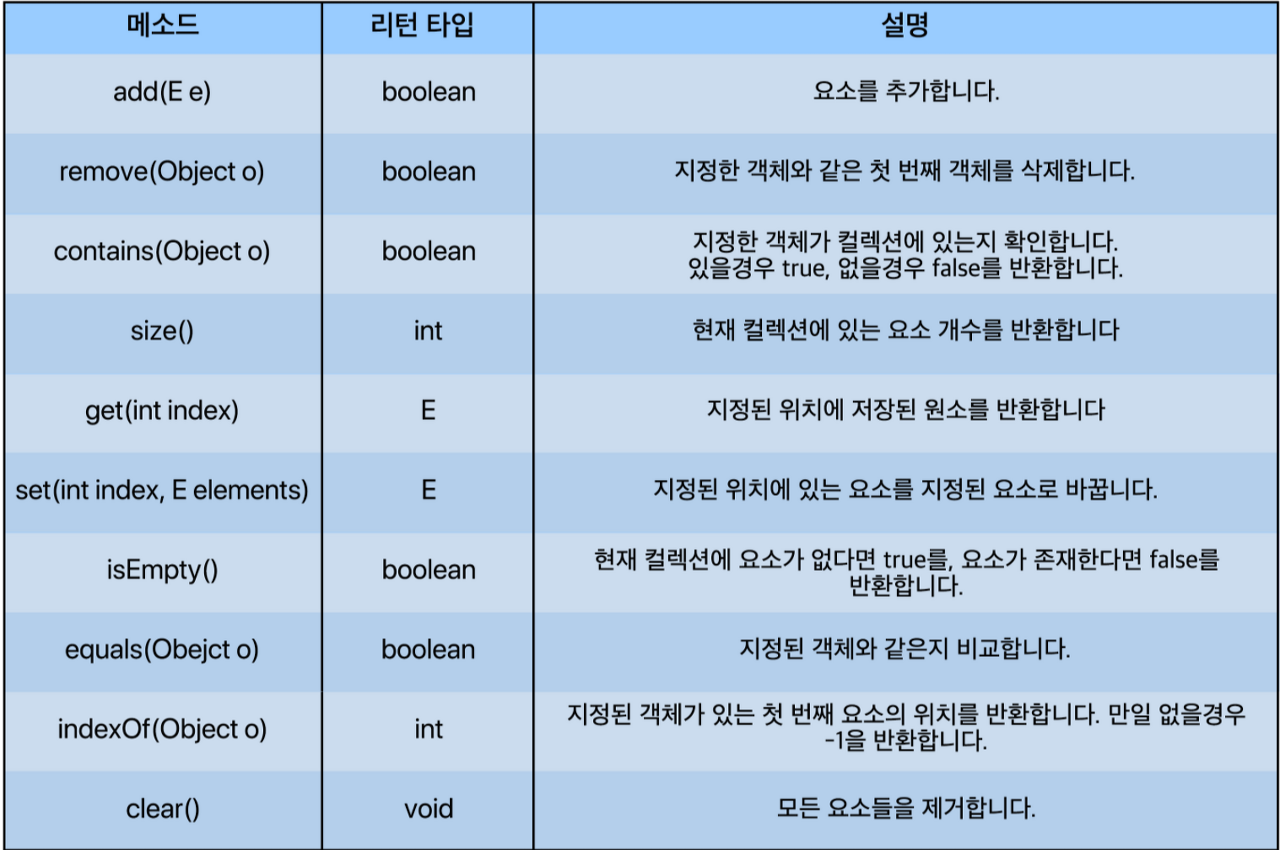
- Set 인터페이스 - 중복❌ / 순서 ❌
- Map 인터페이스 - 중복(키 ❌, 값 ⭕) / 순서 ❌
| void clear() | 해당 맵(map)의 모든 매핑(mapping)을 제거함. |
| boolean containsKey(Object key) | 해당 맵이 전달된 키를 포함하고 있는지를 확인함. |
| boolean containsValue(Object value) | 해당 맵이 전달된 값에 해당하는 하나 이상의 키를 포함하고 있는지를 확인함. |
| V get(Object key) | 해당 맵에서 전달된 키에 대응하는 값을 반환함. 만약 해당 맵이 전달된 키를 포함한 매핑을 포함하고 있지 않으면 null을 반환함. |
| boolean isEmpty() | 해당 맵이 비어있는지를 확인함. |
| Set<K> keySet() | 해당 맵에 포함되어 있는 모든 키로 만들어진 Set 객체를 반환함. |
| V put(K key, V value) | 해당 맵에 전달된 키에 대응하는 값으로 특정 값을 매핑함. |
| V remove(Object key) | 해당 맵에서 전달된 키에 대응하는 매핑을 제거함. |
| V replace(K key, V value) | 해당 맵에서 전달된 키에 대응하는 값을 특정 값으로 대체함. |
| boolean replace(K key, V oldValue, V newValue) | 해당 맵에서 특정 값에 대응하는 전달된 키의 값을 새로운 값으로 대체함. |
| int size() | 해당 맵의 매핑의 총 개수를 반환함. |
| boolean remove(Object key, Object value) | 해당 맵에서 특정 값에 대응하는 특정 키의 매핑을 제거함. |
⭐ArrayList
- 기존의 Vector를 개선한 것으로 구현원리와 기능적으로 동일
- Vector는 자체적으로 동기화처리가 되어 있다.
- List 인터페이스를 구현하므로, 저장순서가 유지되고 중복을 허용
- 데이터의 저장 공간으로 배열을 사용
- 모든 종류의 객체 저장 가능
⭐ArrayList 메서드
- 생성자
- new ArrayList() : 기본 크기가 10인 배열 생성
- new ArrayList(기본크기) : 기본 크기를 지정 (배열이 다 차면 기본크기만큼 사이즈가 증가함)
- new ArrayList<제네릭>() : 배열 값의 타입을 지정
- ※ 제네릭 (Generic)
- 컬렉션 객체를 생성할 때 저장되는 데이터의 타입을 미리 지정하는 기능
- 제네릭으로 지정한 타입 외에는 담길 수 없도록 함
- ※ 제네릭 (Generic)
- 주요 메소드
- .add((index), val): 순서대로 리스트를 추가, 배열 사이즈 초과 시 초기 설정된 사이즈만큼 자동으로 사이즈가 증가함, 인덱스를 추가로 지정해주면 해당 인덱스에 값을 삽입
- .get(index): 해당 인덱스의 값 반환
- .set(index, val): 인덱스로 값 변경
- .indexOf(val): 값을 제공하면 해당 값의 첫번째 인덱스를 반환
- .lastindexOf(val): 해당 값의 마지막 인덱스 반환
- .remove(index or val): 해당 인덱스의 값 or 해당 값 중 첫번째 값 삭제
- .contains(val): 해당 값이 배열에 있는지 검색해서 true / false 반환
- .containsAll(val1, val2...): argument로 제공한 컬렉션의 모든 값이 포함되어 있는지 여부를 true / false로 반환
- .toArray(): ArrayList 타입의 인스턴스를 일반 배열 타입으로 반환, 저장할 배열 타입에 맞춰 자동 형변환, 배열 크기 또한 자동으로 맞춰서 바꿔줌
- .clear(): 값 모두 삭제
- .isEmpty(): 비었으면 true, 하나라도 값이 있으면 false 반환
- .addAll(arr2): 두 컬렉션을 합침
- .retainAll(arr2): argument로 제공한 컬렉션 내에 들어있는 값을 제외하고 모두 지워줌
- .removeAll(arr2): argument로 제공한 컬렉션 내에 들어있는 값과 일치하는 값을 모두 지워줌, retainAll() 메소드와 반대
- .size(): 요소 개수 반환
⭐ArrayList 에 저장된 객체의 삭제과정
- 삭제할 데이터 아래의 데이터를 한 칸씩 위로 복사해서 삭제할 데이터를 덮어쓴다.
- 데이터가 모두 한 칸씩 이동했으므로 마지막 데이터는 null로 변경한다.
- 데이터가 삭제되어 데이터의 개수가 줄었으므로 size의 값을 감소시킨다.
*마지막 데이터를 삭제하는 경우에는 1의 과정은 필요없다.
*ArrayList에 저장된 마지막 객체부터 삭제하면 배열 복사가 발생하지 않는다. (빠르고 깔끔하게 지워진다.)
⭐LInkeList
배열의 장단점
장점 : 배열은 구조가 간단하고 데이터를 읽는데 걸리는 시간이 짧다.
단점 : 크기를 변경할 수 없다. 크기를 변경해야 하는 경우 새로운 배열을 생성 후 데이터를 복사해야 한다.
크기 변경을 피하기 위해 충분히 큰 배열을 생성하면 메모리가 낭비된다.
단점2 : 비순차적인 데이터의 추가, 삭제에 시간이 많이 걸린다.
그러나 순차적인 데이터 추가(끝에 추가)와 삭제(끝부터 삭제)는 빠르다.
- 배열과 달리 불연속적으로 존재하는 데이터를 연결
- 단 한번의 참조변경만으로 데이터의 삭제가 가능하다.
- 한번의 노드 객체생성과 두 번의 참조변경만으로 데이터의 추가가 가능하다.
- 연결리스트, 데이터의 접근성이 나쁘다.
- 더블리 링크드 리스트 : 이중 연결리스트, 접근성 향상(다음 요소와, 이전 요소의 주소를 함께 참조함)
- 더블리 써큘러 리스트 : 이중 원형 연결리스트(다음 요소, 이전 요소, 맨 앞이 맨 끝을 맨 끝이 맨 앞을 참조)
성능비교
순차적인 추가 / 삭제 : ArrayList가 빠르다.
비순차적인 추가 / 삭제 : LinkedList가 빠르다.
접근시간 : ArrayList가 빠르다. (인덱스가 n인 데이터의 주소 = 배열의 주소 + n*데이터 타입의 크기)
⭐스택과 큐
- 스택 : LIFO구조, 마지막에 저장된 것을 제일 먼저 꺼내게 된다.
- 저장(push) / 추출(pop)
- 배열을 가지고 만드는 게 유리하다.
| empty() | boolean | Stack이 비어있는지 알려준다. |
| peek() | Object | Stack의 맨 위에 저장되어 있는 객체를 반환.(확인만 가능 꺼내지는 못함) |
| pop() | Object | Stack의 맨 위에 저장되어 있는 객체를 꺼낸다. |
| push(Object item) | Object | Stack에 객체(item)을 저장한다. |
| size() | Integer | Stack에 추가된 데이터의 크기를 반환. |
| show() | String | Stack에 포함되어 있는 모든 데이터를 String타입으로 변환하여 반환 |
| clear() | 현재 Stack에 포함되어 있는 모든 데이터를 삭제 |
- 큐 : FIFO구조, 제일 먼저 저장된 것을 제일 먼저 꺼내게 된다.
- 저장(offer) / 추출(poll)
- 링크드리스트를 가지고 만드는 게 유리하다.
| add() | Object | 큐에 데이터를 저장한다. |
| poll() | Object | 가장 먼저 저장된 데이터를 큐에서 삭제하고 삭제한 데이터를 반환 |
| peek() | Object | 큐에 가장 먼저 저장된 데이터를 반환 |
| size() | Integer | 큐에 추가된 데이터의 크기를 반환. |
| show() | String | 큐에 포함되어 있는 모든 데이터를 String타입으로 변환하여 반환 |
| clear() | 현재 Stack에 포함되어 있는 모든 데이터를 삭제 |
⭐스택과 큐의 활용
- 스택 : 수식계산, 수식괄호검사, 웹브라우저의 뒤로/ 앞으로
- 큐 : 최근사용문서, 인쇄작업 대기 목록, 버퍼
'2세 > Java' 카테고리의 다른 글
| 231019 - 자바의 정석 chapter 12 (Generics) (0) | 2023.10.19 |
|---|---|
| 231015 - 자바의 정석 chapter 11 (컬렉션 프레임워크2) (0) | 2023.10.15 |
| 230926 - 자바의 정석 chapter 10 (날짜와 시간 & 형식화) (0) | 2023.09.27 |
| 230924 - 자바의 정석 chapter 09 (0) | 2023.09.25 |
| 230921 - 자바의 정석 chapter 08 (0) | 2023.09.21 |
'2세/Java' Related Articles
more

