
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- java map
- java list 출력
- 컴파일
- java최솟값구하기
- 프로그래머스제일작은수
- 격파르타후기
- 항해15기
- 비전공자sqld
- java알고리즘문제풀이
- java set 출력
- 격파르타비전공자
- 코딩부트캠프후기
- java list 저장
- sqld자격증합격
- 항해99후기
- java참조자료형
- java알고리즘
- 인터프린터언어
- 프로그래머스
- 노베이스부트캠프
- 격파르타합격후기
- java map 저장
- javaJRE
- 격파르타장점
- java set 저장
- 작은수제거하기
- javaJVM
- java 자료구조 활용
- java기본자료형
- java map 출력
- Today
- Total
코딩과 결혼합니다
230806 - DB 정규화 하기 본문
🟢 Database 란?
- 구조화된 정보 또는 데이터의 조직화된 모음으로 일반적으로 컴퓨터 시스템에 전자적으로 저장된다. 데이터베이스는 일반적으로 DBMS(데이터베이스 관리 시스템) 의해 제어된다.
- 데이터베이스는 정보시스템의 핵심 요소로 조직 운영에 필요한 데이터를 수집해서 저장을 해두었다가 의사 결정이 필요할 때 처리하여 유용한 정보들을 제공하는 수단이다.
DB의 핵심 개념
1. 공용 데이터
특정 조직의 여러 사용자들이 함께 소유하고 이용할 수 있어야 하는 공용데이터이다.
그래서 사용 목정이 다른 사용자들을 고려해서 구성을 해야한다.
2. 통합 데이터
똑같은 정보가 여러 개 존재하는 걸 허용하지 않는다. 중복을 최소화하고 통제가 가능한 중복만 허용한다.
3. 저장 데이터
데이터는 주로 컴퓨터가 처리하고, 컴퓨터가 접근할 수 있는 매체에 데이터 베이스를 저장한다.
4. 운영 데이터
조직을 운영하고 조직의 주요 기능을 수행하기 위해 꼭 필요하고 지속적으로 유지해야 하는 데이터이다.
🟢 DB 정규화(Normalization)란?
🔹정규화의 기본목표
관계형 데이터베이스의 설계에서 중복을 최소화 화여 데이터를 구조화하는 프로세스를 정규화 라고 한다. 데이터 베이스 정규화의 목표는 이상이 있는 관계를 재구성하여 작고 잘 조직된 관계를 생성하는 것이다.
🔹정규화의 목적
데이터베이스의 변경 시 이상 현상 제거
- 테이블 수정 시, 원치 않던 부작용이 발생할 수 있다.
같아야 하는 정보가 복수 개의 행에서 표현되면, 갱신 시에 서로 다른 정보를 가지게 되는 등의 논리적인 모순을 초래할 수 있다. 테이블에서 특정 데이터를 변경해야 할 시 여러 개의 레코드를 함께 수정해야 한다. 만약 성공적인 갱신이 이루어지지 않을 경우 레코드 중에 일부는 변경되었으나, 일부는 변경되지 않을 경우 그 테이블은 모순 상태가 된다. 이런 현상을 갱신 이상이라고 한다.

- 원하지 않는 데이터가 삽입되거나, key가 없어 삽입하지 못하는 문제점이 발생할 수 있다. 새로운 데이터를 삽입해야 할 때, 그 데이터의 식별칼럼이 null일 경우에 테이블에 추가할 수가 없게 되는데, 이러한 현상을 삽입 이상이라고 한다.

- 어떤 정보를 삭제하는데, 삭제되면 안 되는 다른 사실이 함께 삭제되는 현상이 있을 수 있다. 이런 현상을 삭제 이상이라고 한다.

데이터베이스 구조 확장 시 재디자인 최소화
- 정규화된 데이터베이스 구조에서는 새로운 데이터 형의 추가로 인한 확장 시, 그 구조를 변경하지 않아도 되거나 일부만 변경해도 되는 경우가 있다. 이는 이 데이터베이스와 연동된 응용 프로그램에 최소한의 영향만을 주며, 응용 프로그램의 생명을 연장시킨다.
데이터 구조의 안정성과 무결성을 유지
자료 저장 공간의 최소화
🟢 DB 정규화 절차
함수 종속성을 이용해 릴레이션을 연관성이 있는 속성들로만 구성되도록 분해해서 이상현상이 발생하지 않도록 단계별로 접근하여 수행한다.
*릴레이션 : 관계형 데이터베이스에서 정보를 구분하여 저장하는 기본 단위이다. 결국 릴레이션은 DB 테이블이다.
🔹제1 정규화
같은 성격과 내용의 칼럼이 연속적으로 나타나는 컬럼이 존재할 때, 해당 칼럼을 제거하고 기본테이블의 PK를 추가해 새로운 테이블을 생성하여 기존의 테이블과 1:N 관계를 형성한다.

제1 정규형은 다음의 조건을 만족해야 한다.
1. 각 칼럼(열)이 하나의 속성만을 가져야 한다.
2. 하나의 칼럼은 같은 종류나 타입을 가져야 한다.
3. 각 칼럼이 유일한(Unique) 이름을 가져야 한다.
4. 칼럼의 순서가 상관없어야 한다.
🔹제2 정규화
제1 정규화를 진행한 테이블에 대해 완전 함수 종속을 만족하도록 테이블을 분해하는 것이다.
완전 함수 종속이란 기본키의 부분집합이 결정자가 되어선 안된다는 것을 의미한다.

위의 테이블에서 주민번호를 알면 이름, 성별, 주소를 모두 식별할 수 있다. 그러나 주민번호를 제외한 그 어떤 속성도 다른 속성을 결정할 수 없다.
예를 들어 성춘향이라는 이름을 알고 있다 해서 그의 성별이 여자인지 남자인지 알 수 없으며, 주소와 주민번호 또한 다르기 때문에 이름만으로 다른 속성을 결정할 수 없다. 성별, 주소 또한 마찬가지이다.

이 테이블에서 기본키는 (관서번호, 납부자번호)로 복합키를 가진다. 그리고 (관서번호, 납부자번호)인 기본키는 직급명과 통신번호를 결정하고 있다. 그런데 여기서 관리점 번호, 관서명, 상태, 관서등록 일지 같은 칼럼은 기본키의 부분집합인 관서번호에 의해 결정될 수 있다.
즉, 기본키의 부분키인 관서번호가 (관리점 번호, 관서명, 상태, 관서등록 일지) 칼럼들의 결정자이기 때문에 위의 테이블을 다음과 같이 관서라는 별도의 테이블로 분리한다. 관서라는 이름으로 별도의 테이블을 만들어 관리하면 제2 정규형을 만족시킬 수 있다.

🔹제3 정규화
제2 정규화를 진행한 테이블에 대해 이행적 종속을 없애도록 테이블을 분해하는 것이다. A -> B, B -> C 일 때 A -> C가 만족해 버리면 이행 함수 종석이 발생한다. 제3 정규화는 이행 종속을 없애기 위해 기본키에 의존하지 않고, 일반 칼럼에 의존하는 칼럼이 있다면 이를 제거한다.

이 테이블에서는 A=고객번호, B=등급, C=할인율이 된다. 여기서 등급은 고객 번호에 의해 결정되어지고 있는데, 할인율은 등급에 의해 결정되고 있다. 이럴 때에 문제가 생길 수 있는데, 고객 번호 3의 등급이 Bronze에서 VIP로 변경되었다고 가정해 보자. 이때에는 등급이 높아졌음에도 할인율은 10%로 그대로이다. 물론 등급에 맞게 할인율 또한 변경할 수 있지만, 매우 번거로워진다. 이럴 때에는 아래와 같이 테이블을 분리해 준다.


이제 내 프로젝트에 적용해 보겠다.
기존의 테이블이다.

여기서 "User"에 "gu"와 "dong"은 사용자의 위치를 나타내기 위한 칼럼이다. 일반적으로 한 구에는 여러 개의 동이 속할 수 있으며, "dong"은 "gu"에 종속되고 있다. 완전 함수 종속을 만족하지 못하고 있는 것이다. 따라서 "Location"이라는 테이블을 따로 만들어 관리하는 것이 좋을 것이라는 판단을 내렸다.
이렇게 함으로써 "User"테이블에 "gu"정보가 중복으로 저장되는 것을 방지할 수 있고, "gu"와 "dong"의 정보를 일관성 있게 관리할 수 있다. 또한 새로운 구나 동이 추가되더라도 "Location" 테이블만 갱신하면 되므로 데이터 일관성과 무결성을 유지하기 용이해진다.
또 한 가지 생각해 봐야 할 건 "dong" 이름은 같은데 "gu"가 다른 경우이다.
이 프로젝트에서는 서울만 다루고 있어 서울을 예시로 들자면 아래와 같다.
- 논현동: 강남구와 서초구에 논현동이 있다.
- 상일동: 광진구와 강동구에 상일동이 있다.
- 사당동: 동작구와 관악구에 사당동이 있다.
이 부분은 동과 구에 대한 고유한 id 값을 부여하고 있으므로 딱히 고칠 것 없이 그대로 가면 될 것 같다.
다음은 post 부분인데 '하나의 post는 여러 개의 post_img URL을 가지고 있을 수 있다'는 것을 고려하여 테이블을 따로 만들어 잘 정규화한 것으로 보인다. 다만 ERD를 더 알아보기 쉽게 직관적으로 그리고 구체적으로 보여줄 필요가 느껴졌다. 내가 알아보기 쉬워야 하는데 그렇지 않기 때문이다. 그래서 중복된 단어를 지우고 한글로 표기하고, 어떤 식별자랑 연결되어 있는지 헷갈리지 않도록 참조하는 식별자 이름도 알아보기 쉽게 수정하였다.
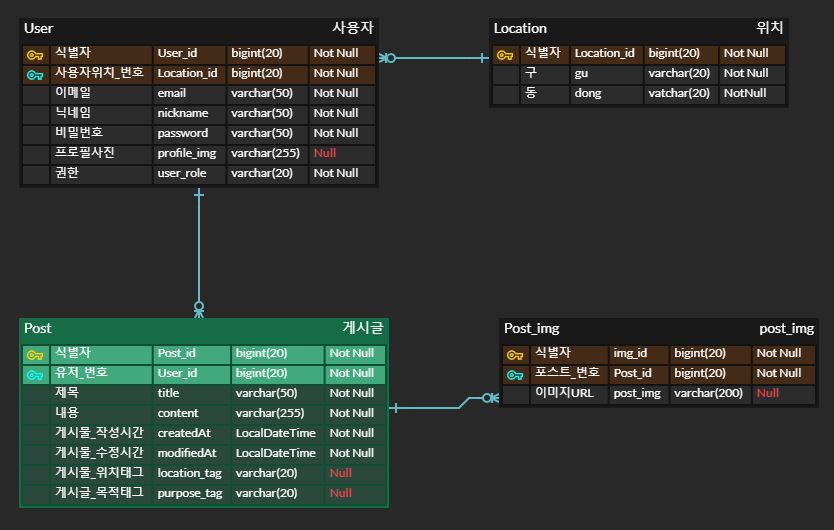
그리고 없어도 큰 상관없는 칼럼에는 Null 을 허용해 준다고 기입하였다.
이렇게 여러 상황들을 고려하여 정규화 과정을 거쳐 ERD를 작성해 보니 '이게 맞는 건가...? 문제없겠지?' 싶었던 이전보다는 자신감과 확신을 가지게 되었다! 앞으로 테이블이 늘어나도 나중에 큰 문제없이 데이터들을 잘 관리할 수 있을 것 같다. (이렇게 보니 정말 엉망이었구나ㅎㅎ)
'코딩과 매일매일♥ > Seoulvival' 카테고리의 다른 글
| 230815 - 코드 리팩토링 멋진 3중 for문을 하나의 for문으로 (2) | 2023.08.15 |
|---|---|
| 230810 - 태그를 누르면 해당 태그의 post가 조회되도록 하기 (0) | 2023.08.10 |
| 230809 - 저장된 태그들로 인기 순위 태그 조회하기 (0) | 2023.08.10 |
| 230804 - SpringBoot 에서 JPA 환경설정 / 기술 스택 선정 이유 (0) | 2023.08.04 |
| 230803 - 파이널 기획 및 S.A (기술 스택 선정과 이유), 오늘 한 일 (0) | 2023.08.04 |



